【采集教程】火车头写规则标签纯正则替换功能的使用教程
-
来源:纯正则替换 浏览:2718次 时间:2020-04-02
【采集教程】火车头写规则标签纯正则替换功能的使用教程
有时候需要用到火车头的纯正则写法去替换某些字词,这个又要怎么写呢?
我们可以通过标签纯正则替换功能,从采集的数据里面提取我们想要的内容,这个功能需要有一定的正则表达式功底,这里重点说明采集器里面如何使用正则,具体的正则是什么意思,可以查资
料研究,这个不是我们教程的重点。
这个功能就是用正则表达式分开来表达我们需要的部分和不需要的部分,然后把需要的那那部分拿出来,不要的那部分就去掉。用下面的一个例子来简单说明下如何在采集器里面使用:
在标签编辑的界面,数据处理那里点击添加,然后选择纯正则替换如下图:

界面如下:

原正则表达式:用正则把需要的部分和不需要的部分分开表示出来,不同部分用括号区分开来
替换后表达式:把需要的那部分放到这里,也可以随意写些别的组合在这里,用采集器自带的表示方式 $1 $2 $数字表示

比如上图我们要从标题里面使用正则把“清纯女生”四个字给提取出来。
使用正则把标题给表示出来如下图:

原理是:用最简单的正则,前面3个汉字做为一组,中间4个汉字做为一组,剩下的是一组。每一组用括号()区分,我们要的是第二组,那么替换后表达式就直接写$2 ,如果要第一组就是$1
按照顺序以此类推。当然正则表达式可以有很多种,小芳也是正则白痴,只能用这种简单的方式来做,高手可以写更好的表达式,原理都是一样的。
采集器里面使用正则的规律就是上面说的那样,先用正则分开表示,用括号区分开来,然后用$1 $2 $数字按照前后顺序依次对应表示结果。
看下测试结果:

测试结果是对的。
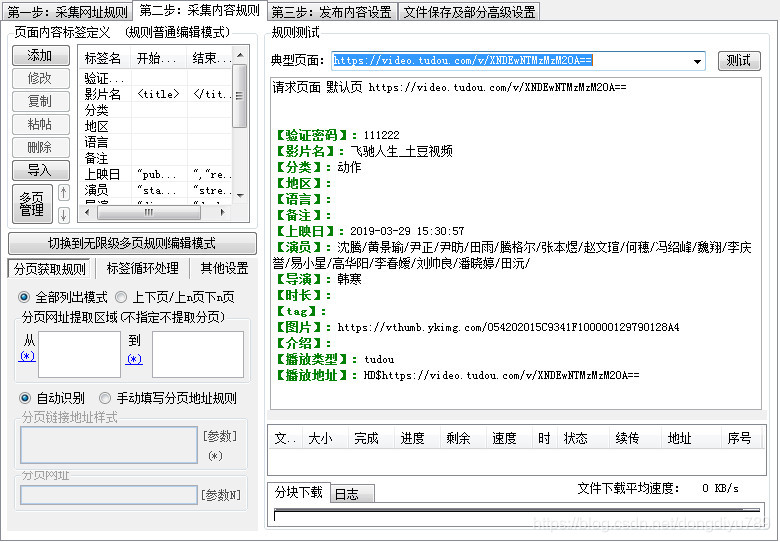
火车头采集器除了正则提取以外,还有一个纯正则替换的功能,在采集一些视频网站的时候,我们大部分都会用到前后截取的功能,但是一旦前后截取的内容不符合标准的苹果cms里边采集内容,就要使用纯正则替换功能了,例如我拿土豆网视频当中的演员
土豆网源码中现在的演员内容是在一段黑色字体当中

我截取这段看看
"stars":[{"id":"312518","name":"沈腾","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005C2477B88B2ABE089C0BA52E"},{"id":"880664","name":"黄景瑜","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005C3717CA8B2ABE089C0387D2"},{"id":"858870","name":"尹正","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005C206CD18B2ABE089C0867A7"},{"id":"396807","name":"尹昉","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F05130000595F00B3ADBA1F051107E775"},{"id":"21280","name":"田雨","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005C762C1C8B2ABE089C0E81F0"},{"id":"358896","name":"腾格尔","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005A8F706A859B5D058E0982C3"},{"id":"846182","name":"张本煜","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F0513000058ABE0D9ADBC09352C0B7E37"},{"id":"12223","name":"赵文瑄","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F05130000589D81F2ADBC090344062EC6"},{"id":"828613","name":"何穗","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F05130000598D248C859B5E02F90C210A"},{"id":"21178","name":"冯绍峰","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005C248178ADA2D40781095892"},{"id":"840372","name":"魏翔","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F0513000058983F8267BC3C6C4B00C2C7"},{"id":"887068","name":"李庆誉","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005A434AFAADA2D406900DEB94"},{"id":"741925","name":"易小星","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005A67FB72859B5E039F0DD104"},{"id":"858655","name":"高华阳","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005A6A890E859B5E05550F20B8"},{"id":"867052","name":"李春嫒","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005CA1E2018B2ABE089C0D45C4"},{"id":"382914","name":"刘帅良","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005CAEF1CCAFB4E3083F0CBF49"},{"id":"278042","name":"潘晓婷","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F0513000059155619AD881A02920D15F9"},{"id":"14528","name":"田沅","thumburl":"http:\u002F\u002Fr1.ykimg.com\u002F051300005CA1E12C8B2ABE089C0BB637"}],"streamtypes"
我们目标是把这段写成正常的苹果cms里边的表达
沈腾/黄景瑜/尹正/尹昉/田雨/腾格尔/张本煜/赵文瑄/何穗/冯绍峰/魏翔/李庆誉/易小星/高华阳/李春嫒/刘帅良/潘晓婷/田沅/
这样的格式
所以我们写纯正则替换前需要了解一下几个字符
.*? 这个是匹配任意字符
([\s\S]*?) 这个也是匹配任意字符
(.*?) 这个把匹配的字符归集成一个组,最后要用$组表达提取出来
节省时间,我已经写出来了
.*?"(.*?)","name":"([\s\S]*?)".*?"(.*?)".*?,
我把每一段的意思说明一下
.*?代表:[{"id":
"(.*?)",代表"312518",
"name"就是原来的那一个
"([\s\S]*?)"代表"沈腾"
.*?代表,"thumburl":
"(.*?)"代表"http:\u002F\u002Fr1.ykimg.com\u002F051300005C2477B88B2ABE089C0BA52E"
.*?代表},
但是这个土豆网在最后强行加了一个}],,这边要注意,.*?虽然代表一切字符,但是有时候需要变一下,最后留一个逗号才可以完美写出,因为前面几个都是有规律的,到最后一个没有规律的话就自已变通一下,改一下就可以完成纯正则替换
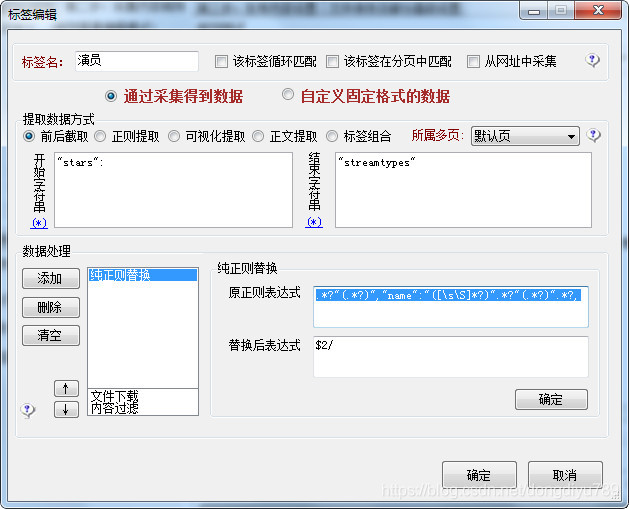
最后替换后表达式$2/,这个代表提取第二个组别,上边我把演员名字归集到第2个组里,所以写法就是$2,后边的/代表每个名字隔开,不然中文字一堆就区分不清楚是哪些演员了。